why ish / 2022-10-14

An experiment in re-organizing the newsletter, based on a list of the values, techniques, and joys I value in traditional open.

I've posted a "why open(ish)" essay, explaining why this newsletter is titled open(ish) and not just open.
tldr: "open" is overloaded, meaning different things to different people, and I have no interest in arguing over those specifics right now. Instead, I am trying to re-learn what open might mean, and so: "open(ish)". This lets me include lots of things that are interesting and relevant to open(ish) values, techniques, and even joy, even if they're not strictly open in an OSI/Open Data Definition sense of the word.
I am experimenting this week with grouping topics by the general outline of that essay; I think it helped me write—curious if it helps you read.
- Intro: anything particularly on my mind that doesn't really fit elsewhere
- Values: entry, governance, legibility, ethics
- Techniques: collaboration, improvement, normative tools
- Joys: humane, radical, fundamental, optimistic
- Change: creation, tooling, regulation, more. (Moved from the beginning of the essay because I think it's mostly obvious that a lot of change is happening!)
Intro: two great starting points
"How Open Source Is Eating AI" is a great essay, summarizing many of the themes I've been hitting in recent weeks. In particular, it has some great points on how open is helping drive massive velocity on a variety of fronts, like cramming down memory usage in one project by about 80% in three weeks.
The State Of AI Report is exactly what it says on the tin: an annual, data-heavy slide deck on AI. Not specific to open, but lots of implications for it, including a few slides I'll discuss below.
Events next week
This past week I was on an ML panel hosted by the Open Source Initiative; next week OSI will also host two more ML panels. Details here: https://deepdive.opensource.org
Values
I think projects that hew to these values are more open(ish); here's some news about how those values are progressing (or not!)
Ease of entry
- VCs and "open": This is not new, but I'd missed it: stability.ai, the entity behind Stable Diffusion, has raised a $100M Series A and says they'll monetize like "normal commercial OSS, with some twists". The demands of VC ROI tend to push towards enclosure, so it'll be important to monitor this. (Also important to consider: the countervailing long-term trend of FAANG-level bigcos emitting code as a "byproduct" of their internal development processes, which appears to be also influencing open(ish) model releases from those same companies.)
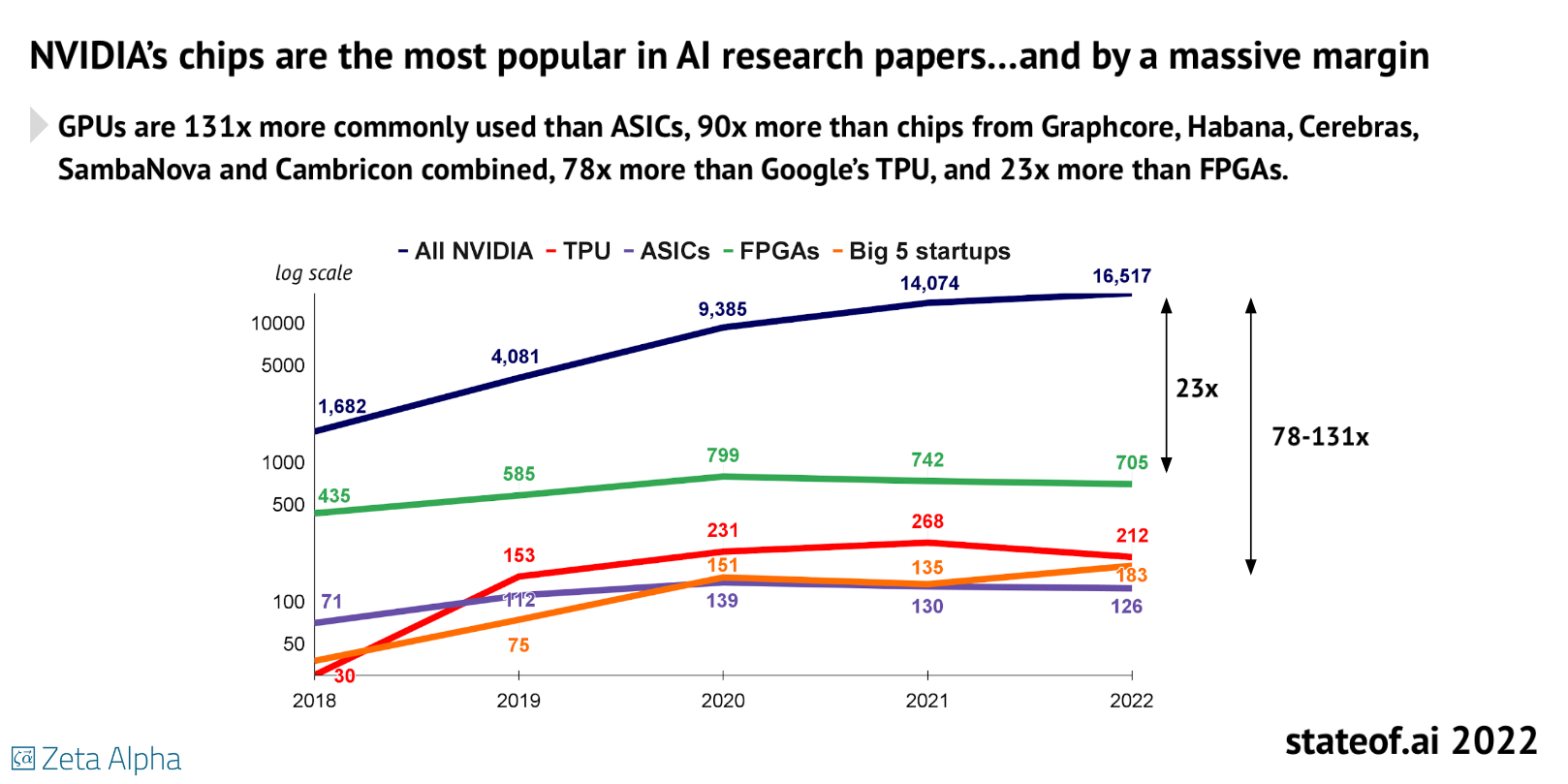
- Nvidia still dominant: I've talked about hardware independence in the last two weeks, but an analysis of published research papers finds Nvidia still extremely dominant—by a factor of 23-100x, depending on the metric. That's not great for open, as it's a chokepoint for entry (both in terms of cost and Nvidia's control).
- Renting tools: This README for a stable-diffusion wrapper script starts with a clear step-by-step on how to rent GPU time. Easily available time-sharing may alleviates some concerns about Nvidia's pricing and supply-chain issues. (I am reminded of the old slashdot joke about "building a beowulf cluster of these" any time new hardware came out; now we just rent the beowulf cluster?)
- More open data: It'd probably be possible to do an entire section just on new open data/model releases, which are critical to ease of entry into this space. My favorite one this week is a dataset of 363 languages for training translation models, mostly Creative Commons licensed, sponsored not by bigtech, but by a non-profit whose primary mission is Bible translation. This is not SIL's first dance in open (old-school folks will recognize them from the name of a popular open font license) but it's a good reminder that this space is not entirely for-profit.
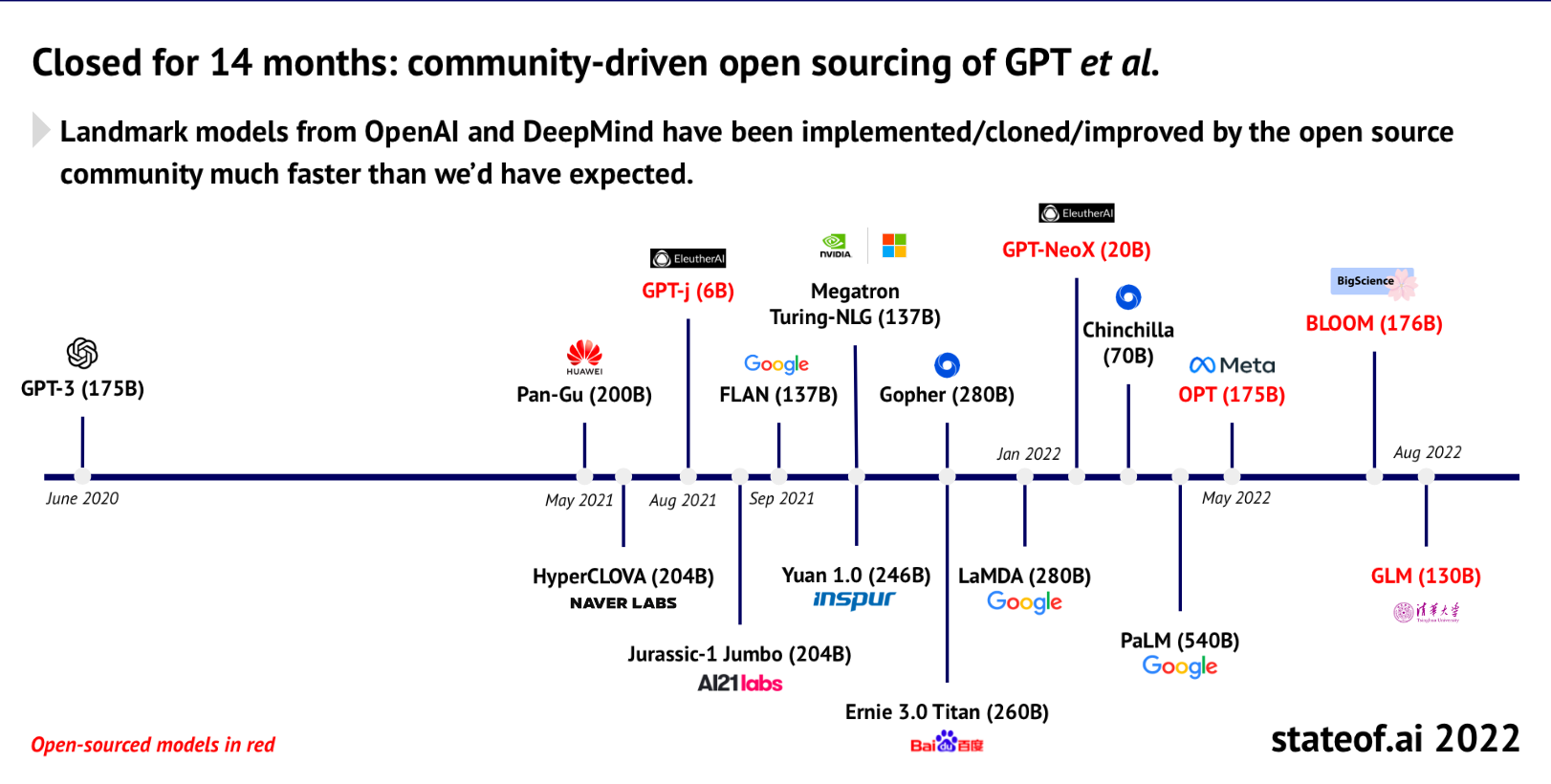
- Change is coming fast: the stateof.ai slide deck has two amazing timelines showing how open(ish) ML has progressed in the past 18 months. The very closed GPT-3 was state of the art for text generation only 14 months ago, and now has meaningfully near-equivalent open competitors. Dall-e's lead as state of the art closed image generation lasted 15 months.
Governance
Open licensing is one part of an overall open(ish) approach to governance. Nothing to report/link here this week, but I have written (for Tidelift) an analysis of the RAIL licenses that builds on my prior analyses of the Hippocratic license and license adoption patterns. Hopefully will publish week of the 24th.
Legibility
A core traditional argument for open was that it made code auditable; the strength of that argument has been somewhat weakened by the vast scope and complexity of the modern stack, making real audits much harder. But there are parallels in ML. Some highlights of that (from either the news this week or my learnings/exploration this week):
- Trustworthy ML: In traditional open, there's (reasonable!) skepticism you can trust any software you can't see the source code of. ML has tried to supplement that by understanding the trustworthiness of outcomes. This is not a new area, but progressing and worth learning about. Couple of resources I've found useful as I go deeper: trustworthyml.org resources page; foundational paper on auditing.
- "Attention maps": A cool, new-this-week demo of one technique lets you highlight (for example) what parts of an emitted picture the ML thought were "bald" or "angry". It's worth playing with it, to help think through how a regulator might use a tool like this to audit ML—either as a complement to, or replacement for, traditional source-available audits.

Techniques
Quiet week here, which of course probably mostly means "I was doing my day job so I missed things" rather than that nothing happened.
Collaboration
Collaboration is a key quality of traditional open, though you won't find it in our formal definitions. Favorite observation on that this week:
- prompt collaboration: This GitHub-maintained Stable Diffusion launcher script includes "prompts to make pictures of your partner look pretty". Put aside the gender issues for a second, and search the script for "ethereal"—that word expands into a longer, more complex prompt. The author is taking patches for the prompts. This is a new class of non-code open collaboration, and is worth keeping an eye on. (The gender issues are also important, of course—I'm curious about when, if ever, we'll see a patch for more traditionally masculine-coded prompts.)
Improvements
In theory, open source allows improvement by anyone; in practice, complexity and other barriers to entry make that hard. But projects that are improveable (both in performance, accuracy, fixes, etc.) are important to the core of open. Things I noticed this week in this space:
- fuzzing, by automated red team: While not widely used, there are a variety of open approaches to "fuzzing"—i.e., feeding an open tool malicious (or simply random) data and seeing what happens. This is from February, so only new to me, but DeepMind has published on how you could use ML to fuzz other ML by emitting prompts designed to elicit bad outputs. It's the bad dinner guest who discusses religion and politics—a "safe" ML would respond to that neutrally, while an unsafe ML might respond in a racist or otherwise undesirable way.
Joys!
I find open fun. Here are some fun things I've seen that remind me of open in the ML space this week:
humane
I love open(ish) most when it helps us be more human. Some highlights of that from this week:
- Prompts as magic: I like that, unlike traditional software, image AIs will create something rather than error out, which encourages wild experimentation in prompts. Simon Willison elaborates a bit on a metaphor for this I love—magic. (Apparently in Japanese they're called "incantations", referring to their magical effect!)
- New(?) art styles: An interesting question for the new tools is whether, given the limitations of their training data and their user interfaces, can artists use them to create truly new stuff, or just regurgitation of earlier ideas? Interesting interview (and cool images) from an artist arguing "definitely yes".
- Optimism as a service: One tiny signal of the change in ML usage is that it is starting to transition from "this can only be deployed by big corporations" to "we can build cool toys with it". This tiny little app takes a negative sentence and reframes it more positively—like turning "I've had a tiring week" into "I had a tiring week, but I'm glad I made it through it". (Both of which happen to be true for me this week!)
Change
What things are being changed by ML (open(ish) or otherwise? What things are changing ML?
Creation
- Copying style... in code? I've been saying "there is no artistic style in code", but this paper tested prompting Copilot with the name of the author of a well-vetted python project—and that reduces vulnerabilities in the code (p.10). Prompting with the name of the author of the paper increases vulnerabilities, oops.
- AI music: If you're already sick of AI-generated art, welp, get ready for AI-generated music from Google and Stability.ai. The Google version purports to limit outputs to non-commercial use; harmon.ai (good name!) is nominally open, but I'm not seeing any details yet on licensing, governance, etc. (If readers have any, I'm happy to share!)
Regulation
- Warhol and AI: This week the US Supreme Court heard a case stemming from Andy Warhol's repurposing of an early picture of Prince. Guessing the Supreme Court on IP issues is usually pointless, but sounds like much of the court was skeptical. AI image companies will want to keep an eye on this one—traditional copyright law could still prove to be a significant constraint in this space.
That's all this week! Hope you continue to enjoy it—please let me know or use the comments on the post.
Discussion