2023, and welcome new subscribers

So I have 30% more subscribers now than I did when I did the last newsletter, which is fun! Welcome to all the new folks. A few things to note/know:
- Beginner’s mind: I’m trying very hard to approach AI with humility—and encourage everyone from “traditional” open to do the same. That’s particularly relevant this week because I’m seeing lots of AI-space writers start the year with 2023 predictions, and I won’t be doing that—there’s still too much I don’t know. (My long-term prediction, though, is here. tldr: as big as the printing press?)
- Open(ish): If you’re new here, you might want to read my essay on open(ish)—where I talk about what traditional open has meant to me and what of that might (or might not) transfer to what I’ve been calling open(ish) machine learning. The most important thing to know is that I find the question “is some-ML-thing OSI-open” to be a nearly completely-uninteresting question.
- Ghost: I use Ghost (an AGPL newsletter/blog tool), but TBH my experience with it has been mediocre so that’ll probably only until I can find the time to switch. So please forgive me if some time in the next few weeks you get a re-subscribe request from another platform.
Smaller, Better, Cheaper, Faster
One of the things that prompted me to start writing this was the change in what tech we thought was necessary to do ML. Two recent notes on that front:
- "Cramming": A paper on training a language model on a single GPU in a single day, and a good Twitter summary of the paper. Results: can reach 2018 state-of-the-art this way. 2018 state of the art is no longer great, and there are reasons to think there are natural limits to this approach, but doing it in one day on one card represents massive progress—especially since they do not enable most hardware speedups, so these wins are mostly because of more efficient techniques and software.
- NanoGPT: Where the previous example used a lot of complexity to save on training time, this MIT-licensed repo goes the other way: training a medium-size language model in a mere 300 lines of code. Like many “small”, “simple” tools, of course, much of the simplicity is because underlying tools (here, PyTorch) provide a lot of power.
I think it’s safe to say that we’re going to continue to see both announcements about high-end training becoming very high-end (vast numbers of expensive GPUs, running continuously) but also increased experimentation at the low end.
Should you use ML tools?
In this newsletter, so far, I've focused less on what “should” happen and more on what the possibilities are: is meaningfully open ML feasible? What would that mean? What impact would that have? Two recent good pieces do touch on that "should" question:
- Friend-of-the-newsletter Sumana has a succinct, practical summary of “should” questions in a post on her use of Whisper, an openly-licensed speech-to-text model. I particularly like Sumana’s use of “reverence” to describe her respect for artists—and her admission that gut feel is a factor (here, in favor of transcription but perhaps against use in art).
- This essay on “ChatGPT should not exist” is more acute than most, getting to the root of a critical question: what does this tooling mean for our humanity? I think ultimately I disagree with the author's conclusion, because I think tool-using is (or at least can be) a critical part of what it means to be human. But I respect the question, and think we'll all have to grapple with real modern Luddism (in the most serious, thoughtful sense of that word) soon.
Wikipedia and ChatGPT
Wikipedia has been having some conversations about ChatGPT (mailing list, English Wikipedia chat). A few observations:
Wikipedia is not as central to ML as it was
5-7 years ago, ML techniques relied heavily on well-structured data like Wikipedia. That’s no longer the case, because the techniques for dealing with unstructured data have become much better, and the volume of training data used has gone way up.
One publicly-documented ML data project—The Pile—can give us a sense of the state of the art. In early 2021, Wikipedia was already a small component:
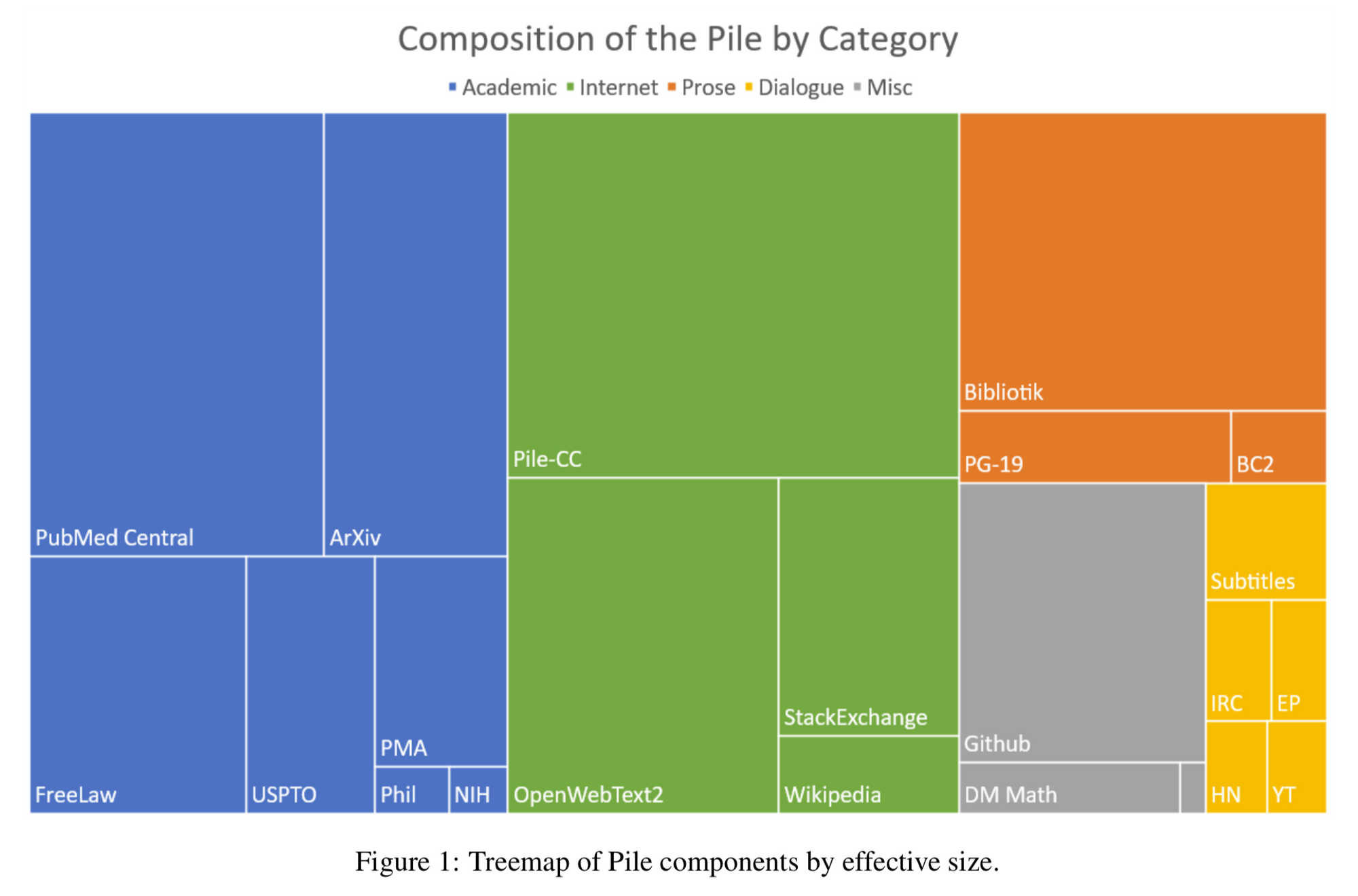
I’ve seen similar numbers in other recent papers. That’s not to say Wikipedia isn’t important (eg this 2022 paper from Facebook relies on it quite heavily), but it’s not essential as it once was, so it now approaches the problem with less leverage than it had even a few years ago.
Good enough?
One discussant pointed out that Wikipedia “thrived because our readers find us ‘good enough’”. This is critical! It’s an easy and common mistake to measure machine learning only against the best of humanity and humanity’s outputs—to understand where ML will have impact, it also has to be compared against mediocre and bad human outputs. (Early Wikipedia, as a reminder, was very bad!) Wikipedia has a better chance than most victims of the innovator's dilemma to collaborate with the new tools—we'll see if that actually happens in practice or not.
Trust shortage as opportunity?
Early Wikipedia benefited a lot from the shortage of simple, credible, fact-centric text on the early internet. It seems likely that soon we'll have a glut of text, while having an even greater shortage of trustworthy text. If Wikipedia can cross that gap, it could be potentially even more influential than it already is.
Creative Commons
I’ve mentioned before that Creative Commons is investigating machine learning, and Creative Common’s most famous user—Wikipedia—is going to be where that rubber meets the road. I don't anticipate a CC5, but it wouldn't surprise me to see a joint announcement of some sort.
An under-appreciated fact about Creative Commons is that it was the first open license, to the best of my knowledge, to explicitly endorse fair use—something since adopted by GPL v3, MPL v2, and other open licenses. In some sense, this is redundant—a license, by definition, can’t take away your fair use rights. But it’s still an important reminder when asking “what does Wikipedia’s license allow” that CC endorses a world where licenses are not all-powerful.
Self-fact-checking?
In the discussion, one Wikimedian claimed that “AI simply can’t discriminate between good research and bad research”. I think that’s probably correct—with two important caveats.
First, humans aren’t actually that good at this problem either—here’s a great article on the shortcomings of peer review. Wikipedia also once happily ingested all of the 1913 Encyclopedia Brittanica, whose commitment to "good research" would be disputed by women, Africans, Asians, etc.
Second, there’s interesting research going on on how to marry LLMs with reliable datasets to reduce “hallucination”. (Google paper, Facebook paper) I’d expect we’ll see a lot more creativity in this area soon, because Wikipedians aren’t the only ones who want more reliability. Wikipedia can engage with this, or (likely) get steamrolled by it.
Misc.
- Stable Diffusion posted a (half)year-in-review thread that’s pretty wild. SD is not traditionally open, but the velocity and variety of deployment and use are verrrry reminiscent of the path of early “real” open techs like Linux, Apache, and MySQL.
- Algorithmic power: In talking about ML regulation recently, it’s been very useful for me to revisit Lessig’s “modalities of regulation”. In this talk by Seth Lazar (notes) he expands on Lessig's “code is law” by going deep on algorithms as power. Given that part of what’s important about “open” is its impact on power, this will be something I'd like to explore more.
- Legal training data? By the nature of the profession, legal data sets for ML training are hard to get at. I was pointed at this one recently, so sharing here, but it’s quite small. I have to wonder if, ironically, ML will be good only at the stuff we do “for fun” because that’s, primarily, what’s on the internet—boring professional work may be more difficult for ML because good data will be harder to find.
- Professional exams: Very related to professional data sets: can GPT pass the bar exam? Not yet. Can it pass medical exams? Not yet. I suspect this particular problem may look a lot like the self-driving car: getting 80% of the way there is doable, but getting further is going to be very hard, in part because of data and in part because of the nuance necessary for professions. But that doesn’t mean they won’t be very useful tools—and potentially replace some specific use-cases—but they won't replace general-purpose lawyers or doctors for a while.
- New art from long-dead artists I’m enchanted by this use of generative ML to re-imagine/extend the career of an artist who died young, 170+ years ago.
- What professors did on their holiday break: I’m seeing many, many examples of professors who spent the break playing with ChatGPT and, in the new semester, experimenting with how to incorporate chatbots into their teaching. One example, of many.
And on a joyful note…
This README is good nerd humor:
My functions were written by humans. … How can I make them more dangerously unpredictable?
Using AI to make arrays of data infinitely long. By filling them with what, you may ask? (The answer, of course, is … filling them with AI! So slow, and probably garbage, and… nevertheless a fun, hopefully harmless, thought experiment…)
Member discussion