getting serious / 2023-03-05

An observation from the Linux Foundation Legal Summit; Apache grapples with ML; adversarial data; memes explained; and muuuch more.

As some of you may have seen on Mastodon, February was rough—I’m still fighting a nasty cold (now in week four). So very slow here. Lots of stuff to share, though. In the interests of Just Getting Something Out, this week may be a little more concise than usual :)
Observation from the Linux Foundation Legal Summit
Mid-month, I spent a day doing an all-day track for open+ML issues for the Linux Foundation’s legal summit, an annual-ish event for lawyers employed by Linux Foundation members. My personal takeaway from conversations during and around the event is that this is a very tough area for attorneys right now: listening to the exact same talk will elicit a wide range of emotions, from curiosity to dread. Much depends on how you, and/or your institution, respond to uncertainty: do you need to control it immediately? avoid it altogether? manage it over time?
I hope that my CLEs in this area nudge lawyers towards that last (proactive, but not controlling, risk management) but it was clear after the LF event there’s still a lot to be done there.
Apache starts to grapple
Apache is starting to grapple with their role in ML, both as a consumer of code that might come from LLMs and a producer of code that might be used to train LLMs.
On the input side, it looks like the current status is “trust developers to use their judgment” rather than a blanket ban.
On the output side, there’s no formal “decision” but some interesting discussion. As with many of these discussions, there remains a strong desire for attribution—but there’s no clear sense of how that might work with current models.
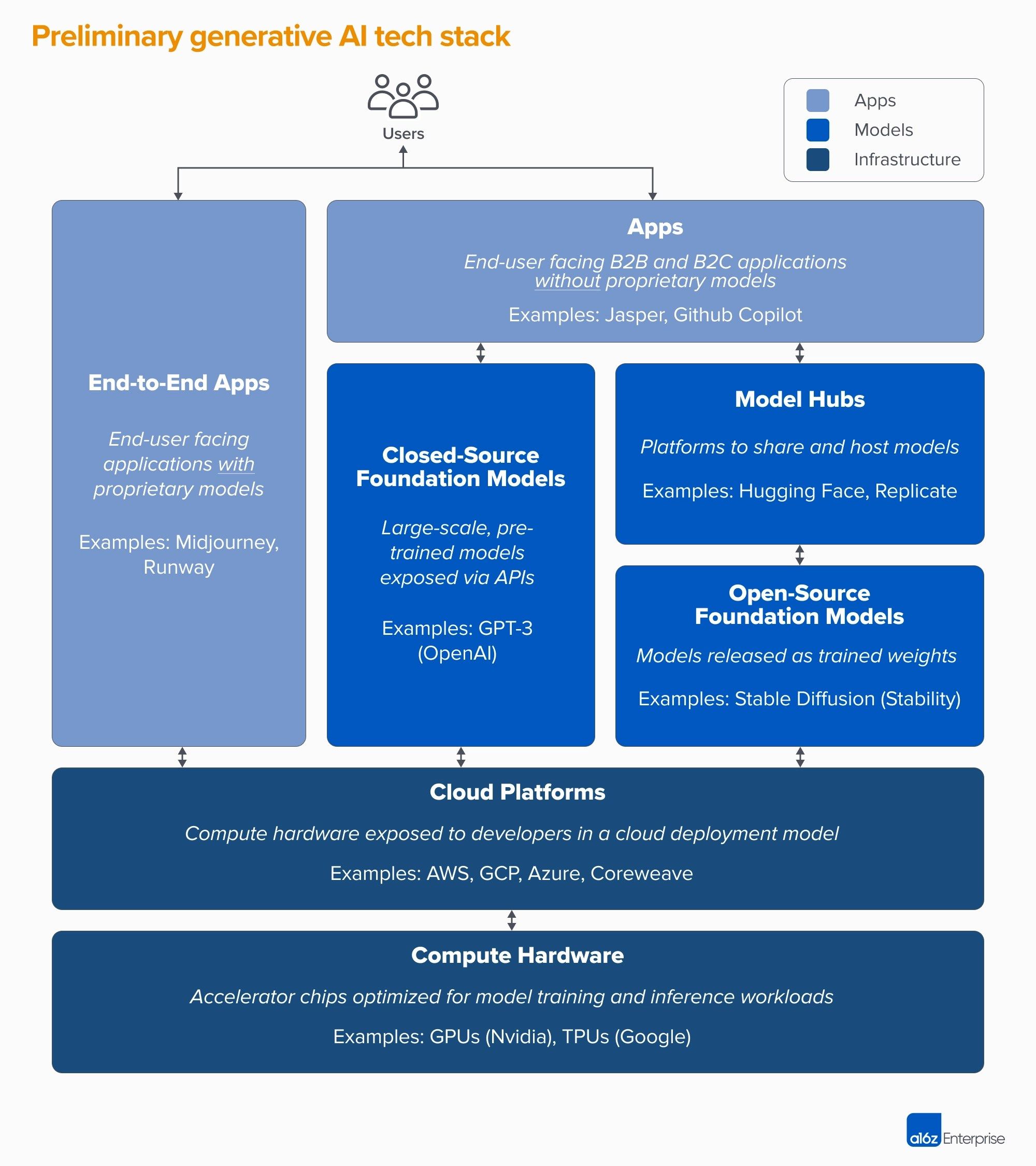
Where open sits in the ML space
a16z’s blog is often more a source of heat than light, but this post on the shape of the ML market is informative. In particular, I think this diagram helps remind us of where value from open(ish) models may accrue — as much or more to hosting services and platforms than as to end-users?
Adversarial data to prevent training?
There’s long been a branch of “adversarial”-tech that attempts to empower individuals by giving them technical tools to defeat technical tools used by others. A classic example is the use of LEDs to blind surveillance cameras.
Recent weeks have brought two experiments in adversarial image processing, attempting to treat photos with alterations that are invisible to humans but confuse various ML algorithms.
- PhotoGuard appears to simply be a proof of concept at this time, but does a good job explaining the core intuitions—and limitations—of such an approach.
- Glaze promises to have tools downloadable soon.
Because it seems likely that there is no “one” adversarial treatment that will confuse all ML approaches, the impact of this seems likely to be minimal. But both the experimentation, and possible uptake, are an interesting signal of how people hope to interact with machines in the future.
Meme explainer time, RLHF edition
Meme break:
Now we know what all the words mean, the picture should make more sense. The idea is that even if we can build tools (like ChatGPT) that look helpful and friendly on the surface, that doesn't mean the system as a whole is like that. Instead... pic.twitter.com/RUXA5yghvD
— Helen Toner (@hlntnr) March 4, 2023
I’ve enjoyed variations on this meme, and the thread (starts here) is a good explainer.
In a related piece, Nathan Lambert of Hugging Face notes that the battle around RLHF is relevant to the question of open models v. closed models, impacting factors like cost and transparency.
What kinds of knowledge can/should be open, colonization edition
First-gen open often assumed (a la Jefferson “light my candle”) that all knowledge should be open. ML is, again, challenging us to reconsider that.
This blog post on indigenous (Maori) language and ML, in the context of the Whisper open(ish) language translation model, is interesting in a bunch of different ways. Among other things:
- Transparency: The team tried to figure out where OpenAI’s training data samples were drawn from, and could not. This is one of those circumstances where the lack of transparency from many model creators interacts very badly with distrust of the (American?) tech industry.
- Fine-tuning as self-determination: The authors try to make lemonade out of lemons by fine-tuning the models with their own datasets, to some success—allowed by the openness of the model. (Similarly, Zulu speakers have achieved much-better-than-ChatGPT results.) I wonder what sorts of open-ness requirements, and/or “fair use training” rights, we will want to provide to empower those who have legitimate cultural concerns about AI produced in other cultures? For example, one could imagine conditioning sale of tools backed by a model on availability of the model to good-faith researchers for improvement and fine-tuning.)
- Ownership of language: “Ultimately, it is up to Māori to decide whether Siri should speak Māori. It is up to Hawaiians to decide whether ʻōlelo Hawaiʻi should be on Duolingo.” The article makes a lot of important points about data quality, documents US tech’s known propensity for releasing tools in non-English languages with only the barest of moderation or quality control, and should raise hard questions for Americans about colonization in a digital era. But this notion of language “ownership” is a very totalizing, centralizing concept. (It’s worth noting that there’s a related strand in content training; while not in the ML context, South Africa was grappling with copyright and folklore in 2021.)
How do we talk about these things?
The question of how we talk about ML has seen some very high-profile pieces in recent weeks that are worth a read. In the New Yorker, Ted Chiang provides an analogy that, while imperfect, is useful, tightly explained, and reasonably concise. And New York Magazine has a long piece on linguist Emily Bender, which helpfully explains the “stochastic parrot” analogy that is often used by critics of large language models.
In a more academic vein, this paper from late 2022 does a nice job reminding us all to “step back” from loaded language.
What do these models “know”?
A common theme of all of the previous three pieces are that models don’t really “know” anything—they’re extremely complex prediction models of whatever it is they’re trained on, so they “parrot” (Bender) or “compress” (Chiang) knowledge without knowing anything themselves.
This perspective is consistent with what we know about how these models are trained, but these models are also large and complex enough that they can still surprise us. In the last newsletter, I mentioned that we expected zero memorization of images in a trained model, and instead are getting small-but-definitely-not-zero memorization.
This week, the surprise is that models trained purely on language may still be forming internal representations of the world. The tool scientists are using to probe this is games. If we train a language model on text strings that represent moves, and then ask it to play the game with us, is it “just” parroting probable strings back at us, or is it actually forming a representation of the game board?
In a simple but elegant experiment, Arvind Narayanan points out that you can just ask Bing what a chess board’s state is after giving it a series of moves—and it’s mostly right!
That chess experiment was inspired by this experiment on Othello (warning: technically deep) that seems to show fairly convincingly that a language model trained solely on descriptions of Othello games (i.e., where you put the next piece) can form a mental model of the game board.
Bottom line: these models may understand and remember better than we currently give them credit, which has definite policy implications—and possibly IP implications as well.
Activism around data practices continues
Alex Champandard of Creative.ai continues to follow in the footsteps of copyleft and privacy activists by publicly probing various providers of data sets and models for compliance with EU law. Worth a follow, both for the details and to help understand how ML users (both open(ish) and proprietary) may face bottom-up “regulation” as well as from regulators like the FTC.

(In one of many parallels between open machine learning and the resurgence of open social networks, I expect we’ll start to see this same sort of activism to test the GDPR compliance of large Mastodon installations soon.)
Why software is bad at predicting things
This is a really terrific systematic approach (based on real-world examples) to the primary reasons why software is very bad at predicting the future. Worth a read for anyone who works at a company that wants to predict things, which is to say, probably most of us.
ML and moderation
In a previous edition I mentioned that moderators would be one of the first groups that felt the brunt of ML-created content. Some real-world data points on that:
- Community consultancy FeverBee does some experiments showing that current-gen ML can generate community bulletin board answers that are pretty good. I suspect we’re going to see a lot more of this, making it harder for moderators to sort wheat from chaff.
- Beloved science-fiction magazine Clarke’s World has had to suspend submissions of short stories because too many of them were ML-generated, flooding their editors. Unclear why this is happening, but it does appear to be enabled by public ML tools/models.
Not moderation per se, but AI-generated voices are now being used to make an old scam more effective.
Data governance
I continue to be interested in data governance as a complement to (replacement for?) data licensing, but with no firm conclusions yet. Some relevant links:
- Survey of Data Cooperatives in Europe
- UK Government says they’ll have a data marketplace by 2024
- Mozilla survey of data governance
Misc.
- Brazil seems poised to adopt a data mining exception to copyright law, similar to the one already in place in Europe that (arguably) protects use of copyrighted materials for ML training.
- What is “Democratization”: If you thought “open” was a contested phrase, welcome to “democratization”. Here's a survey, but I admit that when I see it, I assume it is either a sign of unclear thinking or active whitewashing.
- Definitely not democratizing: In which OpenAI writes an entire blog post on their philosophy of "who should decide", which (1) says that this technology will impact “all of humanity” and (2) does not once mention democracy, governments, or regulation. So the answer to "who should decide" appears to be... OpenAI. But hey, they’ll gather feedback!
- ControlNet: an amazing tool for control of image generation, under an Apache-license; implementation of a Stanford paper. (Discuss amongst yourselves: what does Stanford’s patent office think about this?)
- Huggingface has new toys, aka new GPUs, and asks “what models would you like to see become open”?
- Copyrightability? As has been widely reported, the Copyright Office gave only very thin copyright to a comic book whose visuals were mostly generated by Midjourney. Van Lindberg, who represented the registrant, is a better place to start than most of the media coverage.
- “Open” model releases: Facebook released LLaMa, which they called open, but required a click-through agreement to access and only allowed non-commercial use (among other restrictions). It was nearly immediately made illicitly available.
- What is high risk anyway: Apparently the EU has realized that their proposed regulatory category of “high risk” may be unworkable in the face of large language models exposed to the general public, perhaps upending the entire drafting process of the new AI Act.
Discussion